
(cliquez sur l’image pour ouvrir/télécharger)
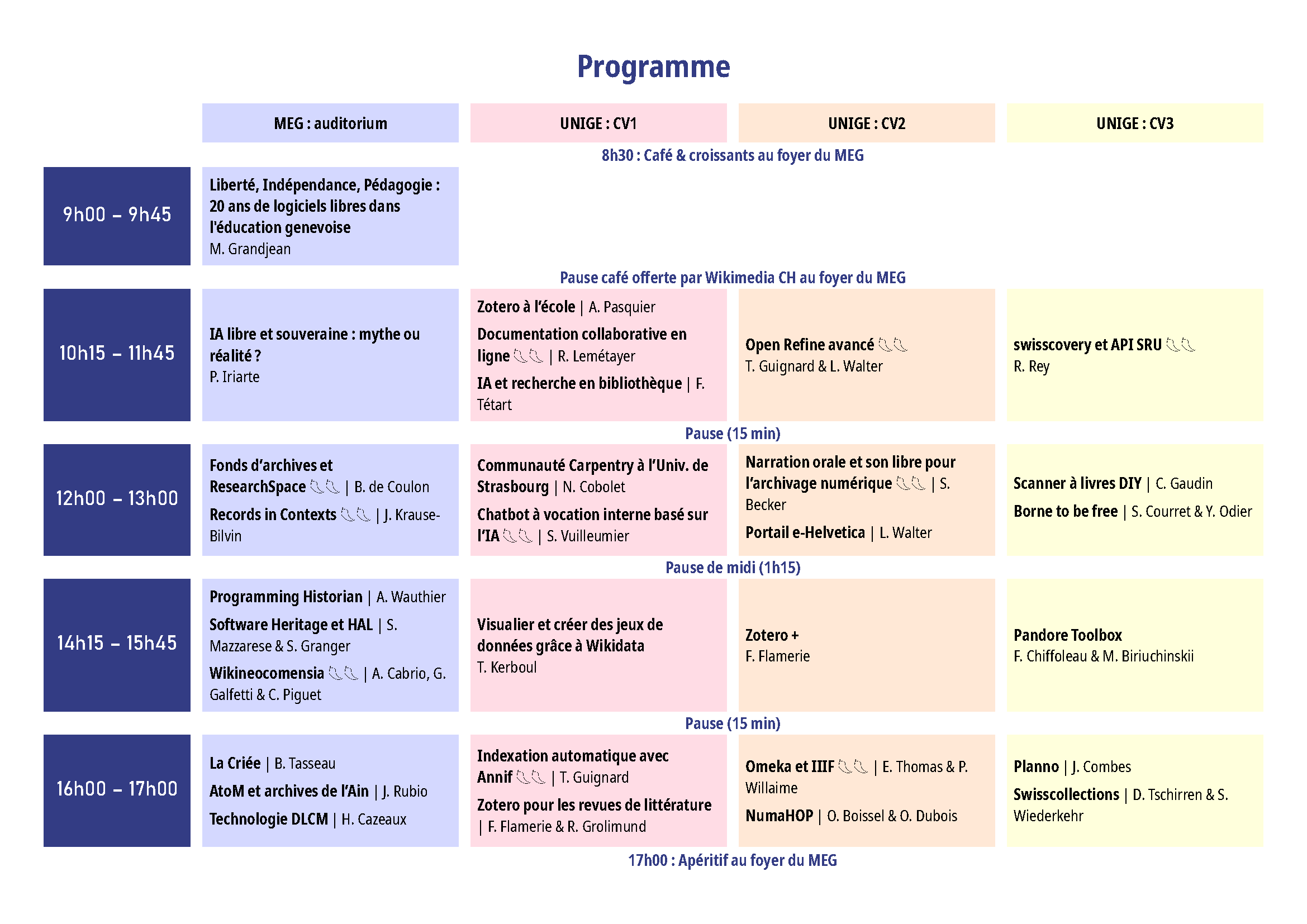
Ci-dessous, vous trouvez la présentation de toutes les interventions, incluant les prérequis.
Liberté, Indépendance, Pédagogie : 20 ans de logiciels libres dans l’éducation genevoise
📜 support de présentation (PDF)
Intervenant : Manuel Grandjean, directeur du Service écoles-médias
Durée : keynote d’ouverture de 45 minutes
Zotero+ : les extensions de Zotero
🌐 support de l’atelier (en ligne)
Intervenante : Frédérique Flamerie, bibliothécaire formatrice indépendante
Durée : atelier de 90 minutes
Niveau : 🌶 débutant
Description :
Vous trouvez que Zotero remplit déjà pleinement son rôle d’assistant de recherche personnel ? Vous n’avez pas encore découvert la myriade de services qu’offrent ses extensions, développées par la communauté de Zotero. Cet atelier est organisé en deux parties. Dans un premier temps, nous explorerons ensemble des extensions telles que Actions & Tags, Linter et Attanger. Toutes permettent d’optimiser l’usage courant de la bibliothèque Zotero : modification des données bibliographiques, gestion des PDF, organisation de la bibliothèque, etc. Dans un second temps, les participant·es seront invité·es à tester une ou plusieurs extensions de leur choix, puis à restituer les résultats de leurs tests. La synthèse de cet atelier pourrait constituer l’ébauche d’une page pour la base de connaissance en français maintenue par le collectif Traduction-Zotero-fr (exemple de page existante).
Prérequis :
* Savoir utiliser l’interface et les principales fonctionnalités de Zotero : gérer une bibliothèque de références bibliographiques et de PDF, citer avec Zotero, afficher le répertoire de données Zotero sur son ordinateur, etc.
* Se munir d’un ordinateur sur lequel est installée la dernière version de Zotero en cours le jour de l’atelier. Il n’est généralement pas nécessaire de disposer des droits d’administrateur pour installer des extensions, mais il est préférable de s’assurer de ce point au préalable auprès de son service informatique le cas échéant.
Zotero pour les revues de littérature
🌐 support de présentation (en ligne)
Intervenant·e·s :
Frédérique Flamerie, bibliothécaire formatrice indépendante
Raphaël Grolimund, bibliothécaire scientifique, Bibliothèque universitaire de médecine (CHUV)
Durée : présentation de 30 minutes
Niveau : 🌶 débutant
Description :
Une revue de littérature comporte plusieurs étapes bibliographiques, de l’élaboration de l’équation de recherche au repérage des articles rétractés, en passant bien sûr par la collecte et l’organisation des résultats de recherche et des fichiers de texte intégral associés. Nous détaillerons comment tirer profit des fonctionnalités de Zotero et de ses extensions (Zoplicate, Linter, etc.) pour chacune des étapes d’une revue de littérature, qu’il s’agisse d’une revue systématique au cadre méthodologique contraint ou d’une revue de littérature intégrée à un travail étudiant.
Visualiser et créer des jeux de données grâce à Wikidata
🌐 support de l’atelier (en ligne)
Intervenant : Thomas Kerboul, spécialiste métadonnées, Bibliothèque de Genève
Durée : atelier de 90 minutes
Niveau : 🌶 débutant
Prérequis : aucun (venir avec un ordinateur)
Description :
Wikidata est une base de connaissances libre et ouverte offrant un accès à des données structurées. Au-delà de la consultation élément par élément, Wikidata permet de visualiser une grande quantité de données sous forme de tableaux, de cartes ou encore de chronologies et de créer ses propres jeux de données grâce au langage SPARQL.
SPARQL (SPARQL Protocol and RDF Query Language) est un langage conçu pour interroger et manipuler des données au format RDF (Resource Description Framework), un modèle utilisé pour représenter des données sous forme de graphe, élément clé du Web sémantique. Toutes les données de Wikidata peuvent ainsi être décrites comme un triplet : sujet – prédicat – objet.
Cet atelier propose une initiation à SPARQL et au Wikidata Query Service. À travers des exemples concrets, notamment en lien avec Genève, l’atelier aborde la structure des données de Wikidata, les composantes essentielles des requêtes SPARQL et la création de visualisations. Au terme de cet atelier, les participant·es pourront créer des requêtes simples à partir du contenu de Wikidata et générer des visualisations ou des jeux de données qu’elles ou ils pourront exploiter directement ou réutiliser, par exemple avec OpenRefine, ou utiliser comme base de départ pour contribuer à Wikidata.
Cet atelier est accessible à tou·tes et ne nécessite pas de compétences préalables en programmation.
Gérez vos plannings en un clin d’œil avec Planno
Intervenant : Jérôme Combes, Chef de produit chez BibLibre
Durée : présentation de 30 min
Niveau : 🌶 débutant
Description :
Planno est un logiciel de planification libre utilisé par des bibliothèques de toutes tailles dans plusieurs pays francophones. Planno permet la réalisation des plannings : de service public, des tâches internes et animations. Il assiste ses utilisateurs en proposant les bonnes personnes pour chaque poste et pour chaque créneau horaire en affichant la liste des agents disponibles et qualifiés. Il s’appuie sur les heures de présence des agents, sur leurs indisponibilités (absences, congés, réunions…) et sur leurs aptitudes pour les différentes tâches à effectuer. Il permet l’utilisation de plannings types qui facilitent le travail et offrent un gain de temps considérable tout en améliorant l’équilibre des plannings et la répartition des tâches. Avec les plannings types, les semaines sont complétées en quelques clics. Les absents sont mis en évidence, il ne reste plus qu’à les remplacer par les personnes disponibles proposées par le logiciel. Planno permet la conception de tableaux personnalisés afin de répondre à chaque situation (semaines, week-ends, périodes scolaires, vacances…). Toutes les informations sont centralisées, il n’est plus nécessaire de vérifier plusieurs fichiers pour connaître la disponibilité des agents. Enfin, Planno propose des rapports statistiques afin d’aider ses utilisateurs dans la conception de plannings équilibrés et équitables.
NumaHOP, plateforme de gestion des contenus numérisés
📜 support de présentation (PDF)
Intervenantes :
Oriane Boissel, présidente de l’association NumaHOP
Olesea Dubois, vice-présidente de l’association NumaHOP
Durée : présentation de 30 min.
Niveau : 🌶 débutant
Prérequis : connaissances des workflows de la numérisation et connaissances de base du contexte français de l’Enseignement supérieur et de la Recherche seraient un plus
Description :
NumaHOP est le premier logiciel Opensource en France à permettre un accompagnement global de la chaîne de numérisation. De l’import de notices bibliographiques à l’export de documents numérisés sur des bibliothèques numériques ou vers de l’archivage pérenne en passant par l’automatisation des contrôles, NumaHOP permet une grande facilitation du processus entourant la numérisation.
NumaHOP est composé de plusieurs modules fonctionnels permettant :
- de convertir des notices au format UNIMARC ou EAD dans des formats interopérables : Dublin Core, Dublin Core qualifié ;
- de réaliser des constats d’état pour les lots de documents à numériser envoyés vers les prestataires de numérisation ;
- de recevoir les lots numérisés par le prestataire (images et métadonnées) et de les contrôler ;
- d’utiliser des fonctions de workflow, de contrôle et de structuration des projets ;
- de valider les unités documentaires numérisées (images + métadonnées) et de les exporter vers les diffuseurs et les archiveurs ;
- de produire des fichiers OCR, METS, images dérivées…
NumaHOP offre la possibilité de disséminer largement et de manière automatisée les contenus numérisés, à la fois sous l’identité des établissements à travers leurs bibliothèques numériques, mais aussi vers des plates-formes externes telles qu’Internet Archive ou OMEKA.
De l’archivage à la citation : Software Heritage et HAL, une solution intégrée pour le logiciel de recherche
📜 support de présentation (PDF)
Intervenant·e·s :
Sébastien Mazzarese, coordinateur des portails HAL et responsable de l’équipe d’assistance aux utilisateurs, Centre pour la Communication Scientifique Directe
Sabrina Granger, open science community manager, Software Heritage
Durée : présentation de 30 min.
Niveau : 🌶 débutant
Description
Malgré son rôle essentiel dans la production de résultats académiques, le logiciel de recherche n’est pas systématiquement inclus dans les politiques institutionnelles en faveur de la science ouverte. Le très faible degré de standardisation des pratiques de citation traduit aussi le fait que le logiciel n’est pas encore considéré comme une ressource ayant sa place dans une bibliographie. Afin d’amorcer ce qui constitue bel et bien un changement de culture tel que l’entend Brian Nosek, Software Heritage et le Centre pour la Communication Scientifique Directe (CCSD) se sont associés pour fournir des services adaptés aux spécificités du logiciel, tout en s’intégrant dans un écosystème plus vaste. Software Heritage est la plus grande bibliothèque de code source ouvert à ce jour. Le CCSD, quant à lui, administre HAL, l’archive ouverte nationale choisie par la communauté scientifique française pour la diffusion ouverte de ses résultats de recherche.
Dans cette présentation, nous nous focaliserons sur trois enjeux dans lesquels les bibliothécaires peuvent pleinement s’investir : rendre les logiciels identifiables ; lier les productions académiques ; préserver et donner accès à long terme aux logiciels. Nous montrerons des solutions opérationnelles tout en les mettant en perspective avec des enjeux auxquels toute institution est confrontée.
Sensibilisation et utilisation de Zotero dès l’école obligatoire : le cas de la Bibliothèque publique et scolaire de la région d’Orbe
📜 support de présentation (PDF)
Intervenante : Aurore Pasquier, Bibliothécaire responsable de la Bibliothèque publique et scolaire de la région d’Orbe
Durée : Présentation (30 minutes)
Niveau : 🌶 débutant
Prérequis : aucune connaissance du logiciel Zotero n’est demandée mais comprendre son fonctionnement peut être un atout
Description :
La Bibliothèque de la région d’Orbe est une bibliothèque mixte regroupant un service public et scolaire. Pour ce dernier, la stratégie a été de miser sur la maîtrise de la culture numérique et des compétences informationnelles dès le passage des élèves au cycle III (secondaire I de l’école obligatoire). Ainsi, l’équipe se déplace dans les classes, auprès d’élèves âgés de 12 à 15 ans environ, au rythme de deux fois par année, en défendant l’idée que l’apprentissage de la gestion de l’information est un savoir-faire pouvant se développer à l’intérieur et à l’extérieur de la bibliothèque.
Le dispositif de formations élaboré par la Bibliothèque illustre quel savoir est attendu aux trois niveaux (9S, 10S et 11S) et permet d’acquérir, via 6 interventions de 50 minutes chacune, les compétences informationnelles nécessaires à maîtriser dont l’organisation/stockage de l’information via un logiciel de gestion bibliographique.
Ainsi, le cinquième module proposé est dédié à Zotero.
Cette présentation répondra aux questionnements suivants :
- Comment est-il possible de déployer Zotero au sein d’un établissement
scolaire ? - Quelles sont les difficultés rencontrées et les leviers utilisés permettant la mise
en œuvre de ce type d’intervention auprès d’élèves de 11S (environ 15 ans) ? - Quels sont les objectifs pédagogiques/didactiques visés et la séquence
pédagogique proposée ?
La narration orale et le son libre pour l’archivage numérique
📜 support de présentation (PDF)
Intervenante : Sandra Becker, GLAM Lead Wikimedia CH
Durée: présentation de 30 min.
Niveau : 🌶🌶 intermédiaire
Prérequis : connaissance rudimentaire du savoir libre
Description :
Dans les cultures indigènes, la transmission du savoir se fait principalement par voie orale. Comment intégrer l’audio dans les projets wiki ? Comment sound peut-il soutenir le savoir libre ? Différentes approches seront présentées.
Records in Contexts : un modèle descriptif flexible et interopérable
📜 support de présentation (PDF)
Intervenant : Jan Krause-Bilvin, chef de projet archivage numérique et co-responsable du modèle de métadonnées, docuteam SA / Conseil international des archives: Expert Group on Archival Description
Durée: présentation de 30 minutes
Niveau : 🌶🌶 intermédiaire
Description :
Records in Contexts (RiC) est un modèle conceptuel de haut niveau permettant la description intellectuelle des ressources, des agents qui les ont créées, des activités menées par ces agents, et des lieux concernés.
En pratique, une mouture technique RiC-Ontology, basée sur des standards du web sémantique offre une interopérabilité technique.
Venez découvrir RiC dans cette présentation, qui s’accompagnera d’exemples concrets dans les domaines des archives, bibliothèques, musées ainsi que dans la gouvernance de l’information.
Pandore Toolbox, une boîte à outils transdisciplinaire
Intervenant·e·s :
Floriane Chiffoleau, ingénieure en humanités numériques, ObTIC/Sorbonne Université
Mikhail Biriuchinskii, ingénieur en traitement automatique des langues, ObTIC/Sorbonne Université
Durée : atelier de 90 minutes
Niveau : 🌶 débutant
Prérequis : un ordinateur avec une connexion internet (wifi eduroam ?)
Description :
Pandore Toolbox est une interface créée par le laboratoire ObTIC, regroupant une diversité de tâches liées aux humanités numériques et au traitement automatique de langues et permettant de travailler à partir d’une image, d’un texte brut ou d’un fichier XML, en fonction de l’outil utilisé. Grâce à cette interface, il est possible de créer une édition scientifique numérique en suivant les diverses étapes (numérisation, transcription, encodage, annotation) ou d’explorer en détail un corpus (extraction de mots-clés, analyse statistique, etc.). Le code source de l’interface est entièrement disponible sur GitHub, tout comme les multiples outils disponibles, et il est également possible d’installer l’interface localement.
Durant l’atelier, animé par Floriane Chiffoleau et Mikhail Biriuchinskii, nous prévoyons de fournir des documents (d’archives ou de bibliothèques) et de faire tester les divers outils aux participant·es, en suivant un processus précis, mais aussi en s’adaptant aux besoins qui pourraient être avancés par les participant·es, afin de leur montrer les multiples possibilités que Pandore renferme et comment ils pourraient l’exploiter à l’avenir.
Borne to be free : transformer un ordinateur ou tablette en borne de prêt
📜 support de présentation (PPTX)
Intervenants :
Sylvain Courret, bibliothécaire-système, BCU Lausanne
Yann Odier, bibliothécaire-système, BCU Lausanne
Durée : présentation de 30 minutes
Niveau : 🌶 débutant pour suivre la présentation, 🌶🌶🌶 avancé pour le refaire chez soi
Description :
Dans le réseau vaudois de bibliothèques Renouvaud, différents membres ont exprimé le besoin de bénéficier d’une borne de prêt simple et économique. L’équipe de Coordination Renouvaud a donc repris une initiative communautaire disponible sur GitHub qui permet de transformer tout ordinateur ou tablette doté d’un navigateur web et d’une douchette code-barres en borne de prêt connectée au SIGB Alma.
Ses fonctionnalités sont limitées, mais répondent à un besoin métier précis : permettre le prêt de documents en l’absence de bibliothécaires au guichet du prêt.
Nous présenterons une instance basée sur une architecture client-serveur. Cependant, la solution peut aussi être hébergée sur un ordinateur ou une tablette, pour des structures aux besoins et moyens plus restreints.
Le code sous licence GPLv3 peut en être réutilisé et personnalisé librement par d’autres bibliothèques. Il est aussi perfectible car des initiatives similaires embarquent plus de fonctionnalités, au prix d’une complexité accrue.
Créer sa documentation collaborative en ligne avec des outils libres : l’exemple de la documentation francophone Zotero
📜 support de présentation (PDF)
Intervenant : Rodolphe Lemétayer, Collectif Traduction-Zotero-fr
Durée : présentation / démo de 30 min.
Niveau : 🌶🌶 intermédiaire
Description :
Depuis 2022, le collectif Traduction-Zotero-Fr propose en ligne la documentation francophone pour Zotero, logiciel libre de gestion de références bibliographiques.
Cette présentation présentera les logiciels et services libres sur lesquels la documentation repose – GitLab Pages, Material for MkDocs, Git, Matomo – ainsi que le format ouvert Markdown utilisé pour la rédaction des contenus.
Vous découvrirez comment le fonctionnement mis en place permet de pouvoir échanger et collaborer sur le contenu, de facilement mettre en ligne les mises à jour ainsi que de traiter les contributions externes.
Efficace et plutôt simple, le fonctionnement de la documentation Zotero-Fr pourra intéresser toute personne souhaitant créer sa propre documentation collaborative.
Mise en place expérimentale d’un chatbot à vocation interne basé sur l’IA
📜 support de présentation (PPTX)
Intervenant : Sylvain Vuilleumier, Spécialiste Ingénierie documentaire, bibliothèque de l’EPFL
Durée : présentation de 30 min.
Niveau : 🌶🌶 intermédiaire
Description :
La présentation décrira le développement d’un chatbot interne basé sur l’IA et utilisant des outils open source.
Confié à l’équipe Ingénierie documentaire de la Bibliothèque, dans le cadre d’une montée en compétences sur les technologies d’intelligence artificielle, ce projet a été construit dans un esprit Proof of Concept.
L’objectif était de simplifier l’accès à l’information contenue dans un wiki regroupant les procédures utiles aux bibliothécaires lors de leurs permanences au guichet (physique et virtuel), pour renseigner les utilisateurs et appliquer correctement les règles de la Bibliothèque.
Le chatbot devait simuler une conversation et permettre aux bibliothécaires de trouver réponse à leurs questions, selon des cas d’usage réels.
La présentation présentera la méthodologie, l’architecture retenue et les étapes-clés : analyse des besoins avec l’équipe en charge du service au public, définition du programme de travail, choix des briques logicielles, déploiement technique, amélioration continue grâce aux retours utilisateurs.
Les premiers résultats montrent une amélioration tangible de l’accès à l’information, confirmant la pertinence de la démarche.
Je serais ravi de partager les enseignements et perspectives issus de cette expérience, qui pourrait inspirer d’autres initiatives.
Omeka et IIIF : des outils pour exposer et partager des ressources culturelles et scientifiques
Intervenant·e·s :
Elisa Thomas, Université Paris Science et Lettres, responsable de la Bibliothèque numérique patrimoniale de PSL / Vice-présidente de l’Association des usagers francophones d’Omeka (AUFO)
Pierre Willaime, Archives Henri Poincaré, Ingénieur de recherche, CNRS / président de l’Association des usagers francophones d’Omeka (AUFO)
Durée : présentation de 30 minutes
Niveau : 🌶🌶 intermédiaire
Description :
Logiciel libre à la croisée du système de gestion de contenus, de la gestion de collections patrimoniales et de l’édition d’archives numériques, Omeka permet de gérer, de collecter, de publier et de partager des contenus et des données de façon simple, flexible et interopérable. Son architecture de base épurée offre la possibilité de s’adapter aux besoins de chaque projet grâce à l’ajout de modules et au choix de thèmes génériques et/ou personnalisables.
Dans une perspective de partage de ressources libres, Omeka s’associe souvent à IIIF, cadre d’interopérabilité ouvert de plus en plus utilisé pour diffuser, agréger, présenter et annoter images, audios et vidéos sur le Web.
Cette présentation proposera un exposé général sur Omeka, son cadre technique, sa modularité et ses articulations avec IIIF. Un tour d’horizon de l’environnement d’utilisation d’Omeka complètera l’exposé en s’attardant sur des exemples de réalisations concrètes dans divers champs d’action, comme la collaboration scientifique ou la valorisation patrimoniale.
Programming Historian en français : les valeurs de la science ouverte au service de la formation en humanités numériques
🌐 support de présentation (en ligne)
Intervenant : Alexandre Wauthier, ingénieur d’études au Campus Condorcet et membre du comité de rédaction de Programming Historian en français
Durée : présentation de 30 minutes
Niveau : 🌶 débutant
Description :
Depuis 2019, Programming Historian en français occupe une place singulière dans le paysage de l’édition scientifique francophone. Fondée sur les valeurs de la science ouverte et de l’open source, la publication fait partie de la famille de revues diamant multilingues Programming Historian (anglais, espagnol, portugais). Elle apporte une légitimité académique aux « leçons » d’humanités numériques grâce à un parti pris fort : un processus d’évaluation par les pairs rigoureux et entièrement ouvert, affiché sur la plateforme GitHub. Très majoritairement consacrées à des solutions libres et toujours basées sur des jeux de données librement accessibles, les leçons de la revue sont des ressources précieuses pour la recherche et l’enseignement. En nous fondant sur des exemples concrets issus de diverses disciplines et adaptés à différents niveaux, nous montrerons comment les leçons de Programming Historian peuvent être utilisées dans le cadre de la formation aux techniques et outils computationnels. Nous aborderons également la fabrication de la revue : son histoire, sa ligne éditoriale, sa communauté, son engagement pour le multilinguisme et la diversité, et son processus d’évaluation ouvert. Enfin, nous expliquerons comment les formateur·ices et enseignant·es en sciences humaines et sociales peuvent contribuer au projet collaboratif de Programming Historian, promouvant ainsi le libre accès et la science ouverte.
La CRIÉE : de la conservation à la valorisation d’un patrimoine éducatif
📜 support de présentation (PDF)
Intervenante : Bénédicte Tasseau, archiviste du DIP
Durée : présentation de 15 min.
Niveau : 🌶 débutant
Description :
Commencée en 1988 et enrichie sans cesse depuis lors, la collection de la CRIÉE (comportant près de 24’400 items) permet de retracer l’histoire de l’école et de l’éducation genevoises grâce aux documents et objets produits par ses acteurs directs (élèves et enseignant·es de tous niveaux scolaires). Cahiers, brochures, dessins, travaux manuels, photos de classe ou matériel scolaire viennent compléter les archives institutionnelles du DIP.
La CRIÉE fait vivre ces archives une fois celles-ci conditionnées et inventoriées en les mettant à disposition du public, qu’il soit professionnel ou non. La CRIÉE leur offre la possibilité de découvrir ce qu’était l’école d’autrefois sous différentes formes (expositions, publications, prêts de matériel, conférences etc.). Cette remarquable collection peut être consultée via une base de données développée à partir du logiciel libre CollectiveAccess.
Depuis 2017, une agente spécialisée travaille à 20% à la CRIÉE, sous la responsabilité de l’archiviste du DIP, pour continuer à accueillir des dons et à les faire exister pour le public. Nous proposons, dans le cadre de cette édition de LibreABC, de présenter la base de données dans sa version publique et dans sa version privée (mode administrateur).
Le portail AtoM des Archives communales de l’Ain
📜 support de présentation (ODP)
Intervenant : Jordi Rubió, archiviste, attaché de conservation du patrimoine, Centre de gestion de la FPT de l’Ain
Durée : présentation de 15 min.
Niveau : 🌶 débutant
Description :
Crée par le Centre de gestion de la FPT de l’Ain en 2015, ce portail basé sous AtoM, logiciel libre et open source développé par l’ICA puis par Artefactual, permet la diffusion des instruments de recherche (ISAD-G) établis par le service archives ainsi que la diffusion des fonds numérisés. Il travaille avec une licence GNU Affero General Public License (A-GPL 3.0).
Leur structure multi institution est particulièrement adaptée à nos besoins car notre établissement gère plus de 300 fonds d’archives et autant d’institutions de conservation. Également, AtoM intègre le référencement des notices d’autorité (ISAAR) ainsi que des institutions de conservation (ISDIAH).
La version actuelle (2.7.3), dont la maintenance est réalisée par l’entreprise Datalib servicios documentales, permet une ergonomie aisée, l’import de fichiers CSV, la création de notices de manière instantanée depuis le portail ou encore l’édition de fichiers structurés à partir des données indexées.
Les données répondent à des standards d’échange de métadonnées qui offrent un import/export aisée. Les formats acceptés sont EAD, EAC-CPF, CSV i SKOS. Le moissonnage des données par le projet Europeana est à l’étude.
Le coût maitrisé, essentiellement lié à la mise en service de nouvelles versions logiciel ou à la création de briques pour améliorer et/ou faciliter l’import des données constitués n’est pas à négliger pour des services avec un budget restaient. L’élargissement du nombre d’utilisateurs serait un atout pour développer des nouvelles fonctionnalités, créer un réseau d’utilisateurs et éventuellement mutualiser des coûts. Nous avons ainsi favorisé le référencement d’AtoM dans le Socle interministériel des logiciels libres de France.
Wikineocomensia : ensemble pour durer
Intervenantes :
Amandine Cabrio, assistante, Service des archives privées et des manuscrits, Bibliothèque publique de Neuchâtel
Géraldine Galfetti, archiviste, Archives de l’Etat de Neuchâtel
Claire Piguet, historienne du patrimoine, Office cantonal du patrimoine bâti et immatériel
Durée : présentation de 30 min.
Niveau : 🌶 débutant-🌶🌶 intermédiaire
Description :
Depuis une dizaine d’années, le patrimoine culturel neuchâtelois est mis en valeur grâce à une collaboration entre plusieurs institutions du canton qui ont fait des projets Wikimédia un outil de valorisation.
Ajout de contenu : complément et correction, création d’article. Amélioration des sources : ajout de références bibliographiques, renvoi à un fonds d’archives. Ajout d’image, à l’unité ou à raison de fonds iconographiques plus conséquents. Partage d’expérience : permanence bimensuelle, organisation d’atelier, formation des apprentis (AID).
Prises individuellement, ces contributions peuvent paraître dérisoires, mais additionnées au fil des ans, elles constituent une solide base de connaissances et de références. Et c’est en partageant leurs expériences, déboires et succès que les membres de WikiNeocomensia n’ont pas abandonné et sont devenues – sans s’en rendre compte – des contributrices averties et de meilleures chercheuses.
À l’occasion de LibreABC, nous souhaiterions revenir sur cette collaboration, ces résultats, ces limites en ouvrant aussi une réflexion sur l’utilisation des projets Wikimédia au sein des institutions culturelles, notamment des archives, des bibliothèques et des services du patrimoine bâti.
swisscollections : la porte d’entrée vers les collections historiques et modernes des bibliothèques et archives suisses
📜 support de présentation (PDF)
Intervenants :
Daniel Tschirren, Directeur adjoint, Zentral- und Hochschulbibliothek Luzern, membre du comité de l’association swisscollections
Stefan Wiederkehr, Bibliothécaire en chef des collections spéciales et de numérisation, Zentralbibliothek Zürich, président de l’association swisscollections
Durée : présentation de 30 min.
Niveau : 🌶 débutant
Description :
L’interface de recherche de swisscollections offre un accès différencié aux collections historiques et modernes des bibliothèques et archives suisses. Grâce à ses nombreuses entrées de recherche, ses facettes et ses index, swisscollections répond aux besoins des chercheurs en matière de recherche de fonds spéciaux. Parallèlement, swisscollections s’adresse aux chercheurs qui utilisent les métadonnées comme données de recherche. Ainsi, swisscollections complète la plateforme nationale des bibliothèques swisscovery, dont l’accent est la mise à disposition des médias au public.
Depuis 2024, les chercheurs en Humanités numériques ont accès à un service d’exportation de données. Ce service inédit et novateur permet aux chercheurs de constituer un corpus thématique à partir de diverses sources de données, de télécharger les métadonnées correspondantes, ainsi que des images dans différentes résolutions et des textes intégraux dans divers formats.
swisscollections réunit aujourd’hui des manuscrits, des fonds d’archives, des estampes anciens, des collections musicales, des images, des cartes et des bibliographies de 14 institutions sous une même interface de recherche. L’accent est actuellement mis sur la Suisse alémanique. L’association swisscollections souhaite étendre l’offre à toute la Suisse et convaincre des institutions de Suisse romande d’y participer.
Aller plus loin avec OpenRefine : API, intelligence artificielle et outils avancés
📜 support de l’atelier (PDF)
Intervenants :
Thomas Guignard, consultant en technologie de bibliothèque et données ouvertes, TG Consulting
Lionel Walter, ingénieur logiciel spécialisé en bibliothèques et archives, arbim IT
Durée : atelier de 90 minutes
Niveau : 🌶🌶 intermédiaire
Prérequis : Cet atelier s’adresse aux utilisateurs ayant déjà des bases solides en OpenRefine. Les participant·es sont invité·es à apporter leur propre ordinateur portable (Mac/Windows/Linux), à y installer le logiciel OpenRefine (libre et gratuit) et télécharger le jeu de données de démonstration avant l’atelier, selon les instructions disponibles sous https://github.com/liowalter/open-refine-libreabc2025.
Description :
Le logiciel open source OpenRefine offre une panoplie d’outils puissants pour nettoyer et explorer des données. Savez-vous qu’il est possible de faire appel à des services externes (via une API) pour aller encore plus loin?
Dans cet atelier, nous utiliserons un service d’intelligence artificielle pour extraire et structurer des informations à partir de données non structurées. Vous verrez ainsi comment configurer et utiliser une API depuis OpenRefine pour effectuer des opérations avancées et récupérer des données externes.
L’atelier inclut des exercices pratiques basés sur un jeu de données complexe et laisse place à l’expérimentation individuelle. Venez découvrir des techniques puissantes pour enrichir vos données en un rien de temps.
Indexation automatique de documents avec Annif
📜 support de présentation (PDF)
Intervenant : Thomas Guignard, consultant en technologie de bibliothèque et données ouvertes, TG Consulting
Durée : présentation de 30 min.
Niveau : 🌶🌶 intermédiaire
Description :
L’indexation et l’ajout de mots-clés reste un outil crucial pour améliorer la découvrabilité de contenu, que ce soit dans un catalogue de bibliothèque ou tout autre base de données. Ce travail souvent manuel peut être long, répétitif et sujet aux erreurs. Il existe cependant des outils permettant d’automatiser en partie ce processus. Dans cette présentation, nous explorerons Annif, un logiciel open source qui exploite plusieurs modèles de langage et l’apprentissage machine pour proposer une solution d’indexation automatique performante et adaptée à son contexte.
Via son interface web intuitive, par ligne de commande ou API REST, Annif permet d’entraîner un modèle sur des vocabulaires multilingues et des corpus personnalisés, puis de proposer des termes d’indexation de manière automatique ou contrôlée.
À travers des cas d’usage concrets, nous verrons comment Annif peut être utilisé comme aide à l’indexation tout comme l’enrichissement automatique de données bibliographiques ou bases de données documentaires.
La technologie DLCM: le couteau suisse de la préservation numérique : données de recherche, données administratives/patrimoniales et innovation
📜 support de présentation (PDF)
Intervenant : Hugues Cazeaux, responsable du groupe eResearch, Service Informatique de l’Université de Genève
Durée : Présentation de 30 minutes
Niveau : 🌶 débutant
Description :
Développée grâce à des financements swissuniversities, la technologie DLCM, proposée en accès libre, permet la préservation numérique à long terme. Cette technologie a été conçue avec le savoir-faire suisse pour construire des solutions complètes d’archivage numérique accessibles via un portail Web simple et ergonomique.
Ses points forts sont : la modularité, l’évolutivité, et l’ouverture de son architecture, qui respecte la norme OAIS et les bonnes pratiques archivistiques. La technologie DLCM:
- facilite le dépôt de données, qu’elles soient issues de la recherche ou des domaines administratifs/patrimoniaux ;
- permet de qualifier les formats soumis automatiquement afin d’informer les utilisateurs des risques d’obsolescence ;
- assure la pérennité des archives en répliquant celles-ci et en garantissant leur intégrité ;
- offre l’accès aux archives grâce à une interface de recherche simple tout en contrôlant l’accès en fonction des niveaux d’accès et de sensibilités des données.
Conçue avec les pratiques logicielles les plus modernes, DLCM garantit une maintenabilité par la mise en œuvre de l’intégration continue et des tests automatiques selon les standards « DevOps ».
Grâce à son évolutivité, l’intégration d’un connecteur ADN, réalisée dans le cadre du projet européen DNAMIC.org, permettra dans le futur d’archiver des paquets d’information dans des molécules.
Rechercher des notices dans swisscovery et d’autres catalogues : comment récupérer des notices avec les APIs SRU
🌐 support de l’atelier (en ligne)
Intervenant : Raphaël Rey, SLSP
Durée : atelier de 90 min.
Niveau : 🌶🌶 intermédiaire
Prérequis : L’atelier s’adresse plutôt à un public débutant avec toutefois quelques connaissances en python.
Description :
Dans cet atelier nous jouerons avec les APIs SRU afin d’accéder aux données du catalogue swisscovery ou Renouvaud. Le propos sera donc sur l’ouverture des données et les outils qui permettent d’y accéder. Parmi les outils, nous aborderons la bibliothèque python almasru. Ces outils permettent d’interconnecter des services en temps réels, ils sont également utiles pour de l’analyse de données. Par exemple :
- Déterminer quelles bibliothèques possèdent un titre
- Vérifier si une notice est reliée à aucune autre comportant des exemplaires et pourrait potentiellement être supprimée
- Vérifier l’existence de notices doublons pour une notice donnée
IA libre et souveraine : mythe ou réalité ?
🌐 support de présentation (en ligne)
🌐 compte-rendu de Grégoire Barbey dans Le Temps du 10 septembre 2025
Intervenant : Pablo Iriarte, Coordinateur Informatique documentaire à la Bibliothèque de l’Université de Genève
Durée : atelier de 90 min.
Niveau : 🌶 débutant
Prérequis : Pour la partie de test sur les LLMs ouverts, une interface Web de type chatbot sera mise à disposition. Les personnes qui voudraient tester ces LLMs sur leur propre ordinateur je recommande l’installation de Python, Jupyter Notebook, et LangChain.
Description :
Depuis le lancement de ChatGPT fin 2022 nous assistons à un développement fulgurant des IA génératives et à une escalade de la part des géants de la Tech. L’adoption par le grand public de ces outils et son intégration progressive dans toutes les sphères de la vie questionne : existent-il des alternatives plus transparentes et fiables ? des IA génératives plus respectueuses de la protection de données et de la vie privée ? des modèles de langage (LLM) entrainés avec des données vérifiés et respectant le droit d’auteur ? des outils moins gourmands en énergie ? qui peuvent être utilisés localement au niveau personnel ou institutionnel ?
Au delà du « open washing », utilisé à tort par certains acteurs, un bon nombre de techniques et outils « open source » ont émergé au tour de l’IA, à commencer par la plateforme Hugging Face, la pléthore de LLMs « ouverts » disponibles gratuitement, ainsi que la palette de logiciels libres associés. L’objectif de cet atelier est de débattre sur tous ces aspects et d’évaluer les possibilités d’appropriation de ces outils et d’une utilisation responsable, individuellement et via l’intégration de ces techniques aux systèmes d’information que nous gérons.
Retour d’expérience : Réalisation et utilisation d’un scanner à livres DIY
📜 support de présentation (PDF)
Intervenant : Cédric Gaudin, président, Musée Bolo
Durée : présentation de 30 min.
Niveau : 🌶 débutant
Description :
Cette intervention présente un retour d’expérience sur la conception et l’utilisation d’un scanner à livres basé sur le projet DIY Bookscanner de Daniel Reetz. Nous détaillerons les étapes clés, depuis le dessin des plans et l’assemblage des différents éléments jusqu’à la mise en service, en mettant en lumière les défis techniques rencontrés. Le projet démontre qu’il est possible de réaliser une solution économique et accessible pour la numérisation de livres et d’archives, permettant de préserver des documents précieux tout en respectant un budget limité. Les points abordés incluront:
- L’assemblage des éléments (base, support des appareils photo, chapeau et chariot),
- Les matériaux et outils utilisés,
- Le choix des appareils photo,
- Le logiciel pour la capture et le traitement des images,
- Une analyse détaillée des coûts du projet,
- Les principales difficultés rencontrées et les solutions mises en œuvre.
Cette présentation s’adresse à toute personne intéressée par la numérisation DIY, les projets techniques accessibles ou la numérisation de documents.
Le nouveau portail e-Helvetica de la Bibliothèque nationale
📜 support de présentation (PDF)
Intervenant : Lionel Walter, ingénieur logiciel spécialisé en bibliothèques et archives, arbim IT
Durée : présentation de 30 min.
Niveau : 🌶 débutant
Description :
La Bibliothèque nationale possède une riche et diverse collection d’objets numériques. Celle-ci inclut, entre autres, des enregistrements audio et vidéo numérisés par la Phonothèque nationale suisse (plus de 50’000 supports numérisés), des livres, des thèses, des articles de périodiques ainsi que l’archive suisse des sites web, qui collecte et archive chaque année plus de 100’000 sites représentatifs.
En 2025, un nouveau portail viendra remplacer l’actuel portail e-Helvetica pour mettre en valeur l’ensemble de ces collections numériques. Conçu entièrement à partir de technologies open source (telles que Solr, NiFi, pywb, ffmpeg, etc.), ce portail proposera une expérience moderne et optimisée. Il est aussi prévu que le code développé pour ce projet soit mis à disposition en open source.
Cette présentation reviendra sur les origines du projet, les défis rencontrés – notamment la gestion d’une volumétrie importante de données issues des archives web en texte intégral ou les contraintes liées aux droits d’auteur pour la consultation des contenus –, ainsi que les étapes de mise en œuvre et les solutions techniques adoptées pour sa réalisation.
Comment gérer ses fonds d’archives sous forme de données liées au moyen de la plateforme libre ResearchSpace
📜 support de présentation (PDF)
Intervenant : Baptiste de Coulon, Fondation SAPA
Durée : présentation de 30 min.
Niveau : 🌶🌶 intermédiaire
Prérequis : intérêt pour la technique informatique
Description :
La gestion des métadonnées archivistiques sous forme de données liées (Linked Data) est au cœur de la nouvelle norme de description Records in Contexts publiée par le Conseil international des archives. Mais quels outils libres peuvent nous permettre de la mettre en œuvre ?
La Fondation SAPA, archives suisses des arts de la scène, utilise en production depuis 2021 les données liées dans son outil de gestion des collections, et le fait depuis 2022, au moyen du logiciel open source GLAM-Community (metaphacts Semantic Platform for Cultural Heritage and Digital Humanities) basé sur la plateforme libre ResearchSpace.
Cette présentation sera l’occasion d’un retour d’expérience sur son utilisation. Comme ces deux outils sont neutres du point de vue du métier, nous expliciterons ce qui est déjà développé pour répondre aux besoins spécifiques des archivistes et ce qui doit encore l’être. Cela sera l’occasion, nous l’espérons, de motiver d’autres institutions à se lancer afin de pouvoir mutualiser de futurs coûts de développement. La présentation se concentrera sur la plateforme en tant que système interne de gestion d’informations archivistiques (SIA/AIS). Nous n’aborderons pas les interfaces dédiées aux publics qui peuvent être prises en charge par d’autres outils.
L’Intelligence Artificielle appliquée à la recherche en bibliothèque
Intervenant : Florent Tétart, directeur de l’innovation, PMB Services
Durée : présentation de 30 minutes
Niveau : 🌶 débutant
Description :
Avec l’intelligence artificielle, la recherche en langage naturel est enfin possible ! PMB intègre désormais une recherche assistée par IA qui comprend les questions des usagers et y répond avec une bibliographie et une synthèse automatique du résultat. Nous présenterons cette fonctionnalité ainsi que les principes sous-jacents de la technologie afin de comprendre son efficacité mais aussi ses limites.
[ANNULÉ] Se former à la programmation pendant la thèse (et après) : retour d’expérience sur la construction d’une communauté Carpentry à l’Université de Strasbourg, France
Intervenante : Noémi Cobolet, chargée de mission science ouverte, Université de Strasbourg
Durée : présentation de 30 min.
Niveau : 🌶 débutant
Description :
En octobre 2021, un premier atelier Data Carpentry a été organisé lors de l’Open Access Week de l’Université de Strasbourg. Puis, l’Université de Strasbourg s’est engagée en devenant organisation membre des Carpentries à partir de 2023. Dès lors, d’autres formations et plusieurs rendez-vous communautaires ont eu lieu. Des personnels ont participé, et de participant·es sont devenus formateur·trices (helpers et instructors selon les termes utilisés par les Carpentries).
Le but de cette présentation est de livrer un premier bilan de cette expérience de formation à la programmation, adressée à des doctorants et des personnels de recherche non informaticien de métier.
Ce sera à la fois l’occasion de revenir sur le projet de formation des Carpentries, vu sous l’angle d’une université participante à la communauté Carpentry d’un point de vue institutionnel. Comment cela fonctionne-t-il concrètement ? Dans la pratique, quel travail reste-t-il à fournir ? Quels sont les fruits obtenus ? Les limites observées et recueillies auprès des équipes participantes, formation après formation ?
Le projet de construction de la communauté Carpentry de l’Université de Strasbourg étant toujours en cours, la présentation sera aussi l’occasion d’aborder les perspectives des formations Carpentry, à l’aune des évolutions en matière de compétences dans la recherche et au sein des services de soutien à la recherche.